浏览器输入URL网址发生的事情
前置知识
进程与线程
进程可以被描述为一个应用程序的执行程序,线程是存在于进程内部并执行其进程程序的任何部分的线程。
进程之间相互独立,同一个进程中的各个线程互相协作,共享一块内存空间。
浏览器架构
浏览器时多进程的,有一个主控进程,以及每一个tab页面都会打开一个新的进程,多个tab会在满足一定条件下合并进程。
Browser:浏览器进程,控制应用程序的“chrome”部分,包括地址栏、书签、后退和前进按钮。还处理 Web 浏览器的不可见的特权部分,例如网络请求和文件访问。Renderer:渲染器进程,控制显示网站的选项卡内的任何内容。Plugin:插件进程,控制网站使用的任何插件,例如 flash。GPU:图形处理进程,独立于其他进程处理GPU任务。它被分成不同的进程,因为GPU处理来自多个应用程序的请求并将它们绘制在同一个表面上。
多进程的好处
避免单个
Tab影响整个浏览器;避免插件影响整个浏览器;
多进程可以高效利用多核优势;
进程有自己的私有内存空间,所以他们通常包含公共基础设施的副本。意味着需要更多的内存使用量,因为如果他们是同一进程内的线程,则无法像他们那样共享它们。为了节省内存,chrome限制了它可以启动的进程数。
方便使用沙盒模型隔离插件等进程,提高浏览器稳定性。
简述版
URL解析DNS解析- 建立
TCP连接 - 发送
HTTP请求 - 服务器处理并返回
HTTP报文 - 浏览器解析渲染页面
- 连接结束
详细版
URL解析为什么做URL解析?
- 网络标准规定了URL只能是字母和数字,还有一写其他符号。转码的过程使用的是
encodeURIComponent进行转码,区别于encodeURI只适用于URL,前者更适用于参数编码
- 输入URL后,浏览器会解析出协议、主机、端口、路径等信息,并构造一个HTTP请求。
- 浏览器发送请求前,根据请求头的
expires和cache-control判断是否命中(包括是否过期)强缓存策略,如果命中,直接从缓存获取资源,并不会发送请求。如果没有命中,则进入下一步。 - 没有命中强缓存规则,浏览器会发送请求,根据请求头的
If-Modified-Since和If-None-Match判断是否命中协商缓存,如果命中,直接从缓存获取资源。如果没有命中,则进入下一步。 - 如果前两步都没有命中,则直接从服务端获取资源。
- 网络标准规定了URL只能是字母和数字,还有一写其他符号。转码的过程使用的是
DNS解析- 在解析过程中,按照
浏览器缓存、系统缓存、路由器缓存、ISP(运营商)DNS缓存、根域名服务器、顶级域名服务器、主域名服务器的顺序,逐步读取缓存,直到拿到IP地址- 检查hosts文件是否有记录,如果有返回对应的映射
IP - hosts文件没有就去查本地
dns解析器有没有缓存 - 然后就去找我们计算机上配置的
dns服务器上是否有缓存 - 如果还没有的话就去找根
dns服务器,然后判断是具体哪个服务器管理,如果无法解析,就去查找.test.com是否能解析,知道查到对应的IP地址
- 检查hosts文件是否有记录,如果有返回对应的映射
- 在解析过程中,按照
Tcp/Ip请求(三次握手)TCP协议是面向连接的,所以它在开始传输数据之前需要先建立连接。要建立或初始化一个连接,两端主机必须同步双方的初始序号。同步是通过交换连接建立数据分段和初始序号来完成的,在连接建立数据分段中包含一个SYN(同步)的控制位。同步需要双方都发送自己的初始序号,并且发送确认的ACK。此过程就是三次握手- 客户端发送
syn包(Seq=x)到服务器,并进入SYN_SEND状态,等待服务器确认; - 服务器收到
syn包,必须确认客户的SYN(ack=x+1),同时自己也发送一个SYN包(Seq=y),即SYN+ACK包,此时服务器进入SYN_RECV状态; - 客户端收到服务器的
SYN+ACK包,向服务器发送确认包ACK(ack=y+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。
- 客户端发送
握手过程中传送的包里不包含数据,三次握手完毕后,客户端与服务器才正式开始传送数据。理想状态下,TCP连接一旦建立,在通信双方中的任何一方主动关闭连接之前,TCP 连接都将被一直保持下去。
- 采用三次握手是为了防止失效的连接请求报文段突然又传送到主机B,因而产生错误。失效的连接请求报文段是指:主机A发出的连接请求没有收到主机B的确认,于是经过一段时间后,主机A又重新向主机B发送连接请求,且建立成功,顺序完成数据传输。考虑这样一种特殊情况,主机A第一次发送的连接请求并没有丢失,而是因为网络节点导致延迟达到主机B,主机B以为是主机A又发起的新连接,于是主机B同意连接,并向主机A发回确认,但是此时主机A根本不会理会,主机B就一直在等待主机A发送数据,导致主机B的资源浪费。
- 采用两次握手不行,原因就是上面说的失效的连接请求的特殊情况。而在三次握手中,
client和server都有一个发syn和收ack的过程, 双方都是发后能收, 表明通信则准备工作完成。 - 采用四次握手没必要。而上面的三次握手已经做好了通信的准备工作, 再增加握手, 并不能显著提高可靠性
浏览器对同一域名下并发的
Tcp连接有一定限制
发送
HTTP请求HTTP的端口为80/8080,而HTTPS的端口为443发送HTTP请求的过程就是构建HTTP请求报文并通过TCP协议中发送到服务器指定端口 请求报文由请求行,请求报头,请求正文组成。
请求行
- 格式为
Method Request-URL HTTP-Version CRLFeg: GET index.html HTTP/1.1 - 常用的方法有:
GET,POST,PUT,DELETE,OPTIONS,HEAD。- GET、POST区别(
GET会产生一个TCP数据包,而POST会产生两个TCP数据包。) - 并不是所有的浏览器都会发送两次数据包,Firefox就发送一次
- GET、POST区别(
- 格式为
请求报头
- 请求报头允许客户端向服务器传递请求的附加信息和客户端自身的信息
请求正文
服务器处理并返回
HTTP报文- HTTP请求一般可以分为两类,静态资源 和 动态资源。
- 请求访问静态资源,这个就直接根据
url地址去服务器里找就好了。 - 请求动态资源的话,就需要web server把不同请求,委托给服务器上处理相应请求的程序进行处理,然后返回后台程序处理产生的结果作为响应,发送到客户端。
- 请求访问静态资源,这个就直接根据
- HTTP请求一般可以分为两类,静态资源 和 动态资源。
断开连接(
TCP/IP四次挥手)刚开始双方都处于
established状态,假如是客户端先发起关闭请求第一次挥手:客户端发送一个
FIN报文,报文中会指定一个序列号。此时客户端处于FIN_WAIT1状态第二次挥手:服务端收到
FIN之后,会发送ACK报文,且把客户端的序列号值+1作为ACK报文的序列号值,表明已经收到客户端的报文了,此时服务端处于CLOSE_WAIT状态第三次挥手:如果服务端也想断开连接了,和客户端的第一次挥手一样,发送
FIN报文,且指定一个序列号。此时服务端处于LAST_ACK的状态需要过一阵子以确保服务端收到自己的
ACK报文之后才会进入CLOSED状态,服务端收到ACK报文之后,就处于关闭连接了,处于CLOSED状态。
浏览器渲染解析页面(
webkit为例)解析过程:
HTML➡DOM树,内容树Bytes→characters→tokens→nodes→DOM
CSS➡CSSOM树CSSOM树 +DOM树 ➡ 渲染树- 浏览器渲染并绘制页面:浏览器会将各层的信息发送给
GPU,GPU会将各层合成(composite),显示在屏幕上- 计算
CSS样式→ 构建渲染树 → 布局,主要定位坐标和大小,是否换行,各种position overflow z-index属性 →光栅化 →绘制,将图像绘制出来
- 计算
光栅化:

浏览器到现在知道了文档的结构和每个元素的样式以及页面的集合形状和绘制顺序,将此过程转换为屏幕上的像素成为光栅化。
- 在最初的光栅化的处理方式是旨在窗口内对部分页面光栅化,如果用户滚动页面,就移动光栅的架子,通过更多的光栅来填充缺失的部分,优点虚拟滚动的那种感觉。
- 现在的方案采用了一种合成的方式,将页面分成多个层,单独光栅化这些页面,并且在合成器线程的单独线程中合并成一个页面。此时如果发生滚动,因为图层被光栅化,所以需要套合成新的框架。
那么如何知道哪些元素在哪些层级中呢?
- 主线程遍历布局树以及对应的创建层数。和 每帧的光栅化的页面小部分相比,为每个元素都提供层,并且合成的话会导致操作很慢。
光栅的合成?
在创建层并且确定了绘制顺序后,主线程将该信息提交给合成器线程。合成器线程光栅化每一层。并且将一个图层分成多个图块并且将每个图块发送到光栅线程。光山县成光栅化每个图层并且将他们存储在
GPU内存中。合成器线程对不同的光栅线程进行优先级排序,以便于首先对视口内容的事务进行光栅化。一个图层也有多个不同分辨率的平铺来处理注入放大操作之类的事情。
对切片进行光栅化后,合成线程会收集称为
绘制四边形的切片信息以创建合成器框架。然后
IPC将合成器框架交给浏览器进程。这些合成器帧会被发送到GPU以将其显示到屏幕上。为什么合成?
- 合成可以在不涉及主线程的情况下完成。不需要等待样式计算或者
js执行。
解析
JavaScript(JS引擎)JS是解释型语言,所以它无需提前编译,而是由解释器实时运行(即时编译(JIT-Just In Time compiler))- 读取代码,进行词法分析(
Lexical analysis),然后将代码分解成词元(token) - 对词元进行语法分析(
parsing),然后将代码整理成语法树(syntax tree) - 使用翻译器(
translator),将代码转为字节码(bytecode) - 使用字节码解释器(
bytecode interpreter),将字节码转为机器码
- 读取代码,进行词法分析(
单线程执行
- 作为浏览器脚本语言,
JavaScript的主要用途是与用户互动,以及操作DOM。这决定了它只能是单线程,否则会带来很复杂的同步问题。比如,假定JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准?
- 作为浏览器脚本语言,
EventLoop(同步任务和异步任务,宏任务和微任务 ):主线程从"任务队列"中读取事件,这个过程是循环不断的,所以整个的这种运行机制又称为
Event Loop(事件循环)。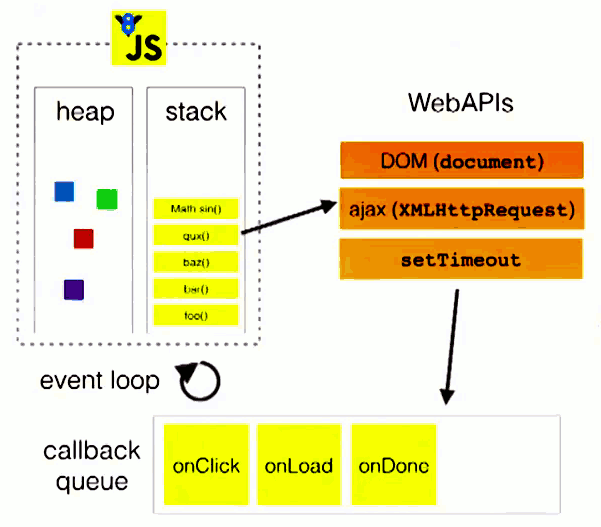
- 上图中,主线程运行的时候,产生堆(
heap)和栈(stack),栈中的代码调用各种外部API,它们在"任务队列"中加入各种事件(click,load,done)。只要栈中的代码执行完毕,主线程就会去读取"任务队列",依次执行那些事件所对应的回调函数。 - 需要注意的是,
setTimeout()只是将事件插入了"任务队列",必须等到当前代码(执行栈)执行完,主线程才会去执行它指定的回调函数。要是当前代码耗时很长,有可能要等很久,所以并没有办法保证,回调函数一定会在setTimeout()指定的时间执行。
回流和重绘:
- 回流:浏览器重新计算
DOM节点宽高位置。一般意味着元素的内容、结构、位置或尺寸发生了变化,需要重新计算样式和渲染树 - 重绘:浏览器在
DOM节点属性确定下来后,绘制内容 - 总结:
- 回流的成本开销要高于重绘,而且一个节点的回流往往回导致子节点以及同级节点的回流
- 回流一定伴随着重绘,重绘却可以单独出现
- 回流:浏览器重新计算